
Accelerators are a type of specialized hardware that enhances the performance of a virtual machine. These include Graphics Processing Units (GPUs), Field-Programmable Gate Arrays (FPGAs), and machine learning chips. Cloud Service Providers install accelerators in the hardware of high-intensity virtual machines. For AWS, this is the Accelerated Computing family, and for Azure, this is the N-series. Tailpipe calculates emissions for GPUs and machine learning chips. FPGAs are excluded from the calculation methodology, due to the lack of reliable data on their power consumption.
Neither provider delivers data on accelerator utilization to their customers as standard. In order to track accelerator utilization, customers of AWS and Azure must load additional software onto their instances. This would need to be automated by the organization’s DevOps team. When customers do have this software loaded, Tailpipe uses the utilization data directly from the Cloud Service Provider.
It matches this utilization data against the power draw of different accelerators at specific utilization loads. Tailpipe has lab-tested a range of accelerators using a load testing software that tracks utilization at 5% increments. This data reveals what proportion of an accelerator’s Thermal Design Power (TDP, measured in Watts) is drawn at each 5% utilization increment. Tailpipe uses this data to draw a generalized power consumption curve for accelerators depending on the utilization rate, which is matched to the client usage. The power curves are:
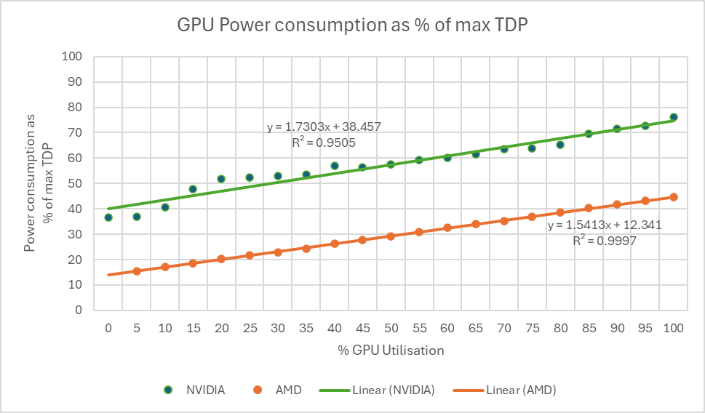
So, an NVIDIA GPU with a TDP of 300 W, being utilized at 50%, will draw 57% of the GPU’s maximum TDP:
0.57 * 300 = 171 W
Tailpipe has lab-tested GPUs from NVIDIA and AMD (see Appendix A), which are the most common GPU manufacturers utilised by cloud service providers. Azure only uses AMD and NVIDIA GPUS, but AWS also utilises a small number of Habana Labs and Qualcomm GPUs, as well as AWS’ own architecture, the Inferentia and Trainium machine learning chips. Habana Labs GPUs are matched to the NVIDIA power curve, and Qualcomm GPUs are matched to the AMD power curve, due to similarities between these manufacturers’ specifications.
AWS does not release any data on the power consumption or TDP of its Inferentia and Trainium chips, but does draw a comparison between the Trainium and P5e families: ‘Trn2 instances offer 30-40% better price performance than the current generation of GPU-based EC2 P5e and P5en instances’. Tailpipe therefore allocates Trainium GPUs a TDP of 600, based on the NVIDIA H200 Tensor Core GPUs utilised by the P5e family.
Hugging Face conducted tests on the Inferentia chips that drew comparisons with the AWS G5 family. Tailpipe therefore allocates the Inferentia chips a TDP of 150, based on the NVIDIA A10G Tensor Core GPUs utilised by the G5 family.
The methodology used by Tailpipe for users who have enabled accelerator utilization tracking is therefore:
Accelerator Energy Consumption (Wh) = (TDP Power Factor * Accelerator TDP) * Hours of Utilization * Number of Accelerators
When customers do not have utilization tracking software enabled, Tailpipe assumes that accelerators are being utilized at a rate of 60%. This is based on a statement made by a principle generative AI architect at Alphabet, that ‘the utilization rates of GPUs for AI workloads in a datacenter run by cloud service providers (CSP) is between 60% and 70%’ (as reported in Tom’s Hardware, 2025).
The methodology used by Tailpipe for users who do not track accelerator utilization is therefore:
Accelerator Energy Consumption (Wh) = (60% TDP Power Factor * Accelerator TDP) * Hours of Utilization * Number of Accelerators
Where the 60% TDP power factor for NVIDIA, Habana Labs, and AWS accelerators is 0.60055, and for AMD and Qualcomm accelerators is 0.32644.



